El LVM (Gestor de volúmenes lógicos, Logical Volume Manager) es una de mis funcionalidades preferidas en Linux. En esta y posteriores entradas intentaré explicarlo de la forma más sencilla posible para que los que no lo usaron nunca se adentren en él.
De forma simplificada podríamos decir que LVM es una capa de abstracción entre un dispositivo de almacenamiento (por ejemplo un disco) y un sistema de ficheros. En realidad pueden existir múltiples capas, como cifrado con device-mapper, raid software con md, etc. por encima o debajo de LVM. Pero para empezar diremos que LVM estará entre nuestros discos físicos y los sistemas de ficheros (o swap, o almacenamiento de máquinas virtuales,…).
Las ventajas que tienen son múltiples, pero la inicial y más evidente es la flexibilidad frente al particionado tradicional. Pongamos (sin LVM) que creamos 4 particiones contiguas en un disco. Si en el futuro quisieramos aumentar alguna de las 3 primeras no podríamos hacerlo sin borrar las siguientes, lo que es complejo, peligroso y requiere de parada del servicio casi seguro. Pongamos que quisieramos ampliar la última, siempre tendríamos el límite del tamaño del disco. Pongamos que compramos un disco nuevo, y queremos ampliar el espacio de un sistema de ficheros existente en el disco anterior con el espacio nuevo, imposible salvo con «ñapas» de nuevos sistemas de ficheros y puntos de montaje. Con LVM todas esas limitaciones desaparecen. Podemos aumentar sus «particiones» (volúmenes lógicos en adelante) independientemente de que no haya espacio libre contiguo a éstas. Podemos aumentar sus volúmenes lógicos con espacio libre de diferentes discos físicos. E incluso podemos mover volúmenes lógicos entre dispositivos físicos. Y lo mejor de todo… ¡en caliente! Sin desmontar el sistema de ficheros, ¡sin parar un servicio! ¡Brujería! ¡Brujería!
Las ventajas no terminan ahí, y procuraré repasarlas todas en lo sucesivo. Pero empecemos hablando de nomenclatura. Para entender casi por completo el LVM debemos tener muy claros únicamente tres conceptos (y que el concepto es el concepto):
- Volumen físico/Physical Volume (PV). Un volumen físico (PV en adelante) es un dispositivo de almacenamiento, o más correctamente expresado un dispositivo de bloque. Puede ser un disco duro, una partición, una tarjeta SD, un floppy, un dispositivo RAID, un dispositivo loop (que convierte un fichero a un dispositivo de bloque), un dispositivo cifrado, ¡incluso un volumen lógico (LV) puede usarse de PV!. Para simplificar diremos que un PV es una fuente de almacenamiento, es decir un dispositivo que nos proporciona espacio. En el ejemplo más sencillo: el disco duro de nuestra máquina, o una partición en él. Un PV no hay que formatearlo, simplemente se le entregará al LVM «en crudo» y desde ese momento será gestionado por el LVM, no volveremos a tocarlo.
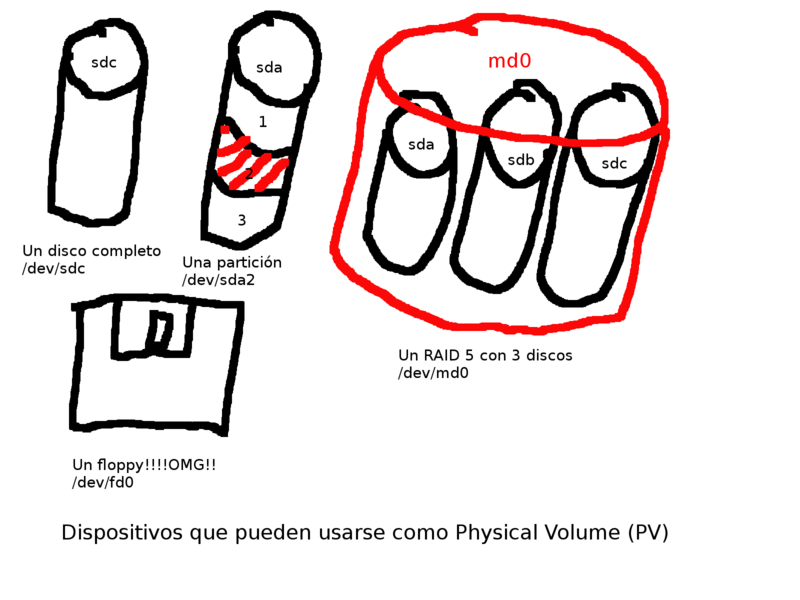
Dispositivos que pueden usarse como PVs
- Grupo de volúmenes/Volume Group (VG). Para poder usar el espacio/almacenamiento de un PV, éste debe pertenecer a un Grupo de volúmenes (en adelante VG). El VG será el centro del universo LVM. Podemos decir que un VG es una especie de disco duro virtual (ya veo a los puristas rasgándose las vestiduras). Un VG es un «disco» compuesto de UNO o más PVs y que crece simplemente añadiendo más PVs. A diferencia de un disco real, un VG puede crecer con el tiempo, sólo hay que «darle» un PV más. En una máquina con un sólo disco podemos crear un VG que esté compuesto por un sólo PV (el disco físico o una de sus particiones). Si con el tiempo nos quedamos sin espacio en el VG, compramos otro disco (PV), lo añadimos al VG y el resto es transparente para sistemas de ficheros, procesos o usuarios. ¡Magia negra!
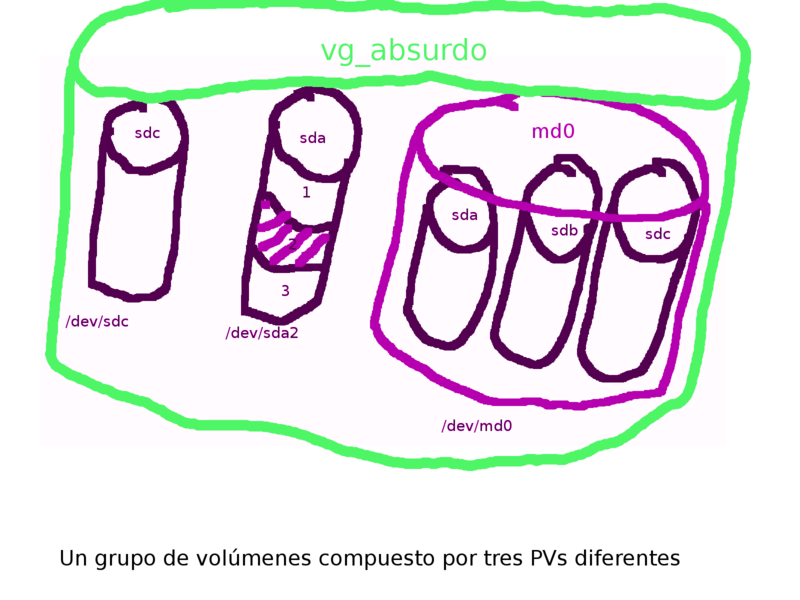
Un VG con nombre acorde a su composición: vg_absurdo
- Volumen Lógico/Logical Volume (LV). Los volúmenes lógicos (en adelante LV) son «el producto final» del LVM. Son estos dispositivos los que usaremos para crear sistemas de ficheros, swap, discos para máquinas virtuales, etc… Por seguir con la analogía del «disco duro virtual» que es el VG, los LVs serían las particiones. Con los que vamos a trabajar realmente. A diferencia de «sus primas» las particiones tradicionales, los LVs pueden crecer (mientras haya espacio en el VG) independientemente de la posición en la que estén, incluso expandiéndose por diferentes PVs. Un LV de 1G puede estar compuesto de 200MB procedentes de un disco duro, 400MB de un RAID software, y 400MB de una partición en un tercer dispositivo físico. El único requisito es que todo los PVs pertenezcan al mismo VG. Por supuesto, aunque posible, no parece una combinación con mucho sentido 😛
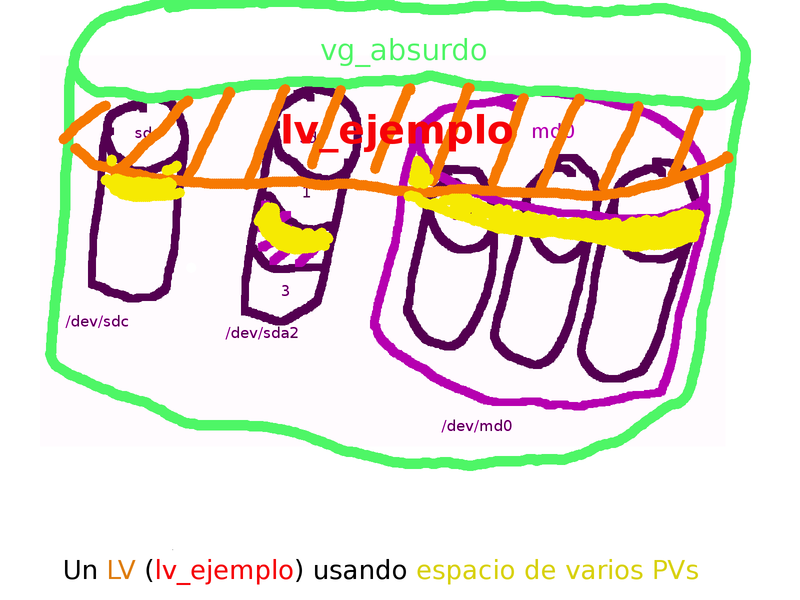
Un LV (lv_ejemplo) dentro del VG (vg_absurdo) usando espacio de 3 PVs
Perdón por los dibujos, el día que repartían «venas artísticas» no fui al cole. La idea es visualizar los diferentes componentes. Que agrupamos PVs para dar forma (tamaño) al VG, y que con el espacio del VG podemos crear LVs. Los LVs de un VG pueden usar espacio de uno o varios PVs, por supuesto seremos nosotros los que decidamos de que PVs sacamos el espacio que compone un LV. El ejemplo actual no tiene mucho sentido ya que tenemos un LV (pensemos en una «partición») que tiene partes redundadas (el espacio que viene del RAID) y partes que no (el espacio asignado desde el disco o la partición), o partes más rápidas (posiblemente el RAID) y partes más lentas. En este VG (insisto, un tanto extraño) podríamos tener LVs que sólo usaran espacio del disco, y LVs que sólo usaran espacio del RAID, lo que tendría algo más de sentido. En cualquier caso lo normal es que los PVs que forman un VG tengas características (redundancia, velocidad) similares.
Otra ventaja del LVM que ya podemos ver es que los nombres de los componentes los elegimos nosotros, lo que facilita su comprensión. Al crear un VG o un LV, somos nosotros los que decidimos sus nombres. Por tanto nos alejamos de cosas «raras» como sda5, md3, etc. y pasamos a una nomenclatura que nos ayuda a comprender que hay en cada LV:
# Ejemplos de nombres para VGs y LVs # Un VG para producción, posiblemente con RAID como PVs # Los nombres de los LVs permiten saber que es lo que contienen /dev/produccion/datos /dev/produccion/aplicacion # Un VG para desarrollo, tal vez sin RAID y con discos "baratos" /dev/desarrollo/datos # Una máquina con discos internos y con acceso a una cabina de discos /dev/interno/raiz /dev/interno/swap /dev/cabina/web
Con estos términos claros podemos explicar mejor la flexibilidad del LVM con unos ejemplos:
- Un LV puede crecer siempre que haya espacio libre en el VG al que pertenece. El LVM se encarga de que lo que haya sobre el LV (frecuentemente un sistema de ficheros) vea todo el espacio continuo. Podemos crear inicialmente un LV usando espacio de un PV, pero si posteriormente queremos aumentarlo, aunque no quede espacio en el PV original, podemos usar espacio de cualquier PV que pertenezca al VG. Para el sistema de ficheros será transparente.
- Podemos cambiar el espacio asignado de un PV a un LV a otro PV (que tenga espacio suficiente libre). Me explico, yo puedo crear un LV de 10G en un PV que sea un disco. Si posteriormente meto en el VG un PV que sea un RAID, podría mover los 10G que estaba usando del disco al RAID, en caliente y de forma transparente al sistema de ficheros y las aplicaciones que lo usan. De forma que si con el tiempo puedo mejorar el hardware de la máquina, no tengo porque volver a crear un sistema de ficheros, copiar los datos y cambiar el montaje. Con LVM simplemente digo: los 10G del LV que están en un PV los quiero mover a un PV diferente. Y el hará la mudanza sin interrumpir el funcionamiento del sistema.
- Para poder disfrutar al máximo de la flexibilidad del LVM es importante tener la mayor cantidad de espacio libre en el VG (volveré a este tema más tarde), pero tarde o temprano nos quedaremos sin espacio en un VG (porque usemos todo el espacio de sus PVs). Bien, esto, que tradicionalmente es bastante complicado de gestionar, con LVM es tan sencillo como darle otro PV al VG. Añadimos un disco (PV) a la máquina y lo asignamos al VG, que pasa a tener todo ese espacio nuevo disponible para cualquiera de los LVs que contenga. O para crear LVs nuevos.
La idea, al menos de esta primera ventaja que nos presta el LVM, es que el almacenamiento no nos imponga límites «artificiales». Nada de particiones que no pueden crecer porque les sigue otra en el disco. O discos que una vez llenos no podemos seguir usando sin hacer malabares. El espacio de mis dispositivos está ahí a mi disposición, para que lo use como me convenga. Para crecer mientras haya espacio libre, para mover los datos entre dispositivos sin que tenga paradas en el servicio. En resumen, los megas son mios y los uso como quiero.
En la próxima entrada empezaré a hablar de los comandos para la gestión del LVM y estarán mucho más claros todos esto ejemplos y funcionalidades. ¿Preguntas? Pon un comentario e intentaré resolverlas.
$ exit