Si mis dibujos no te dejaron muy claro los conceptos básicos del LVM no te preocupes, ahora lo explicaré desde el principio con los comandos de gestión del LVM. Seguro que quedará más claro.
Empezar de cero a montar LVM en un sistema ya en marcha no es lo más común, ya que lo ideal es hacerlo en el momento de la instalación, pudiendo así incluir todos los discos por completo. Casi todas las distribuciones permiten hacerlo automáticamente, aunque el resultado final no suele ser ideal (ver Consideraciones finales). Cuando comprendas el funcionamiento podrás usar el instalador de tu distribución para crear una estructura LVM personalizada que tenga más sentido que la que propone el instalador sin preguntar.
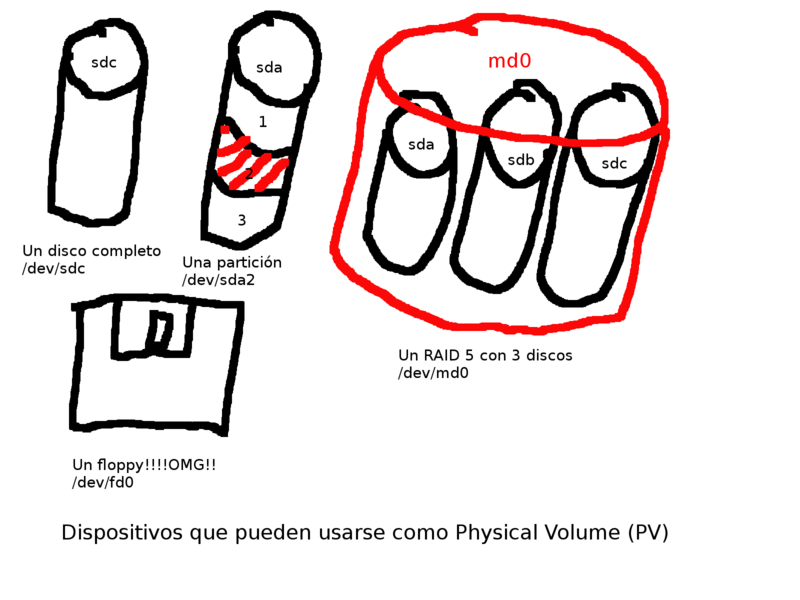
Entregando dispotivos de almacenamiento al LVM (PV)
El primer paso para usar LVM es decidir que dispositivos de almacenamiento queremos usar. Pueden ser discos, dispositivos RAID por software, particiones, etc. Lo más importante en este paso es que al LVM le daremos el dispositivo para que lo gestione y, salvo raras excepciones, no volveremos a tocar el dispositivo directamente. Nada de darle una partición al LVM y luego crear un sistema de ficheros en ella. Dicho de otra forma, no le toques los PVs al LVM.
La forma de entregar un dispositivo al LVM es marcarlo como un Physical Volumen (PV). Cuando vayas a crear un PV asume que la información que contenga hasta ese momento ya no es tuya, dala por perdida. Así que cuidado con equivocarse con el nombre del dispositivo en el comando pvcreate. Este comando básicamente indica que desde su ejecución el dispositivo indicado como argumento pasa a ser de dominio del LVM. Ejemplos:
# Estos comando deben ser ejecutados con el usuario root # Normanlment los usuarios no pueden jugar con los discos :-) # Marcar el primer disco, por completo, como PV pvcreate /dev/sda # Marcar varias particiones como PV pvcreate /dev/sda3 /dev/sdb1 /dev/sdc1 # Marcar un dispositivo RAID por software como PV pvcreate /dev/md0
Una vez «marcado» un dispositivo como PV, podemos ver información del mismo con los comandos «pvs» y «pvdisplay«:
# pvcreate /dev/vda3 Writing physical volume data to disk "/dev/vda3" Physical volume "/dev/vda3" successfully created # pvs PV VG Fmt Attr PSize PFree /dev/vda3 lvm2 a-- 400.00m 400.00m # pvdisplay /dev/vda3 "/dev/vda3" is a new physical volume of "400.00 MiB" --- NEW Physical volume --- PV Name /dev/vda3 VG Name PV Size 400.00 MiB Allocatable NO PE Size 0 Total PE 0 Free PE 0 Allocated PE 0 PV UUID q2noaK-2apE-kkGe-MnNA-IzuE-ICDY-3MiKns
En este ejemplo cabe destacar el tamaño del PV, /dev/vda3, 400M, que están por completo libres y que en la columna «VG» (del comando «pvs«) o la fila «VG Name» (en «pvdisplay«) no hay ningún valor. Es decir, el PV está a disposición del LVM pero no pertenece a ningún VG, por lo que por ahora no podemos usarlo (Allocatable NO). Por ahora no entraré en la definición de PE, no quiero meter más conceptos y no es necesario a estas alturas.
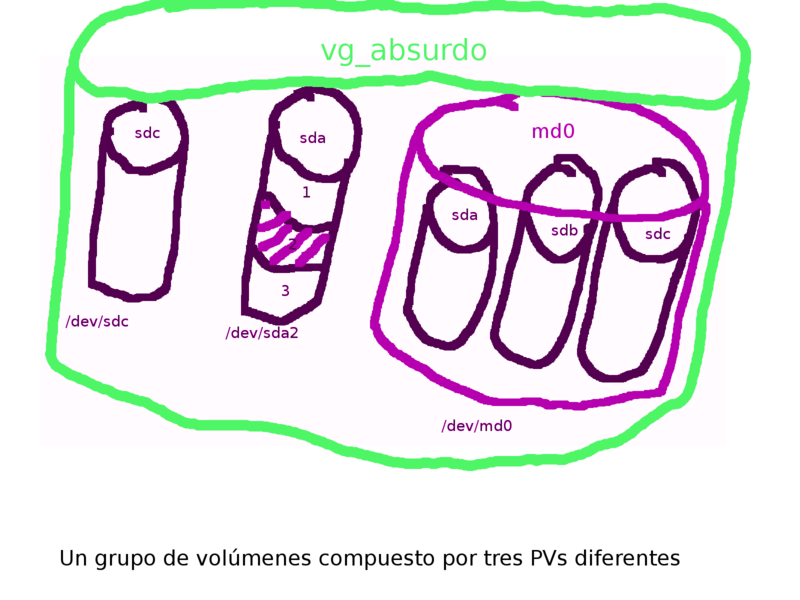
Creando un Grupo de Volúmenes (VG)
Como comenté en la entrada anterior, un VG es una especie de disco duro virtual. Su tamaño viene dado por la suma del espacio de los PVs que lo componen. Y es del espacio disponible en el VG de donde crearemos los Volúmenes Lógicos (LVs, algo similar a las particiones). Son los LVs los que finalmente usaremos para crear sistemas de ficheros, espacio para swap, discos para máquinas virtuales, etc.
El comando de creación de un VG es extremadamente sencillo. Simplemente le daremos como primer argumento el nombre del VG que estamos creado y a continuación el/los dispositivo(s) (marcados como PVs previamente) que queremos que lo compongan:
# Creando un vg llamado "multimedia" con un PV vgcreate multimedia /dev/vda3 Volume group "multimedia" successfully created # Creando un vg con más de un PV vgcreate produccion /dev/sdb /dev/sdc /dev/sdd Volume group "produccion" successfully created
Importante en este punto es dar un nombre identificativo al VG. Una de las ventajas del LVM es que vamos a poder dar nombre significativos a nuestro almacenamiento. No pierdas esta ventaja llamando a los VGs algo como «vg00». Yo tengo VGs llamandos «raid» y «sinraid» en máquinas que tienen parte de los discos en RAID y otra parte no. Ese nombre me permite, a la hora de crear un LV, saber si mis datos estarán protegidos (y/o acelerados) por el RAID o están en un simple disco. Tengo máquinas que tiene un VG llamado «interno» (formado por los discos físicamente dentro de la máquina) y otro llamado «cabina», porque sus discos están en una cabina externa. Igualmente podríamos tener «producción» y «desarrollo», o «sistema» y «datos». Para gustos los colores, pero aprovecha el poder elegir el nombre 🙂 Huelga decir que es mejor evitar símbolos especiales (como espacios), acentos, eñes y esas cosas que podrían dar problemas en nombres de dispositivos.
Una vez creado el VG podemos ver información del mismo con los comandos «vgs» y «vgdisplay«:
# vgs VG #PV #LV #SN Attr VSize VFree multimedia 1 0 0 wz--n- 396.00m 396.00m # vgdisplay --- Volume group --- VG Name multimedia System ID Format lvm2 Metadata Areas 1 Metadata Sequence No 1 VG Access read/write VG Status resizable MAX LV 0 Cur LV 0 Open LV 0 Max PV 0 Cur PV 1 Act PV 1 VG Size 396.00 MiB PE Size 4.00 MiB Total PE 99 Alloc PE / Size 0 / 0 Free PE / Size 99 / 396.00 MiB VG UUID xuYff2-maw7-0ldW-PiLv-xZ6F-NFa3-3gNPod
Con estos comandos podemos comprobar que nuestro VG se llama «multimedia», está compuesto de un PV, todavía no tiene ningún LV creado y dispone de 396MB libres. Las Physical Extensions (PE) son las unidades de asignación mínima del LVM. Por defecto son de 4MB (aunque se puede cambiar en la creación del VG). Es decir, cada vez que creemos un LV lo haremos en múltiplos de (por defecto) 4MB. Pero esto no es algo que os deba preocupar por ahora.
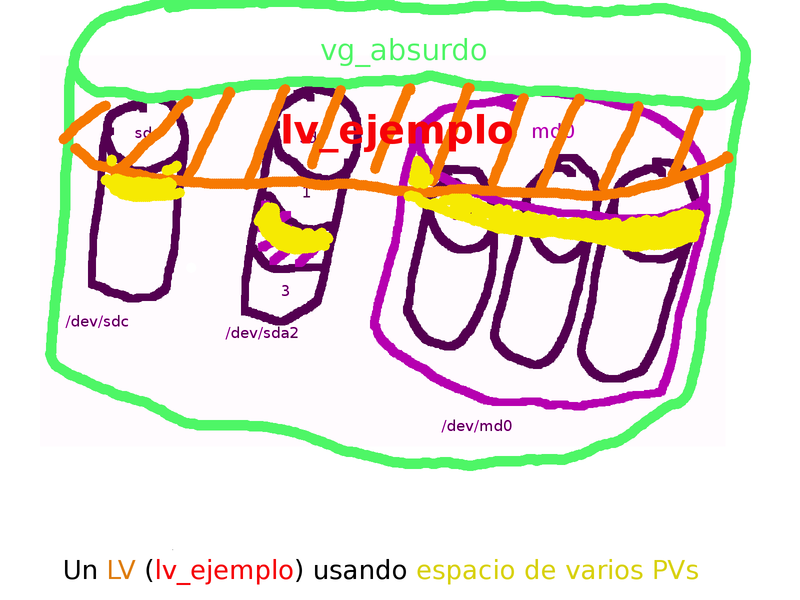
A por el producto final, Volúmenes Lógicos (LV)
Una vez tenemos un VG ya podemos crear los dispositivos que realmente usaremos. Los volúmenes lógicos (LV) pertenecen a un VG, del que toman su espacio. Pueden crearse, borrarse y crecer sin necesidad de reiniciar la máquina o parar servicios (bueno, para borrarlos hay que dejar de usarlos primero, obvio).
Un LV puede usar espacio de un solo PV, o de varios. En este último caso puede deberse a que vaya creciendo con el tiempo, y ya no quede espacio en el PV original, o que al crearlo hemos decidido que use varios PVs (por motivos de rendimiento, por ejemplo). Pero esto lo veremos en próximas entradas del blog. Por ahora nos centraremos en la creación de un LV simple.
Para crear un LV, con el comando lvcreate, debemos indicarle el VG al que pertenece (como argumento del comando), el tamaño (en PEs con la opción -l o en megas/gigas/teras con -L) y optionalmente, pero muy recomendable, el nombre que queremos darle (-n). Emplos:
# Un LV de 40MB en el VG multimedia para guardar música lvcreate -L 40M -n musica multimedia # O especificando el número de PEs (de 4MB por defecto) lvcreate -l 10 -n musica multimedia
Una vez más, aprovecha para darle un nombre representativo del contenido que habrá en él. Desde este momento la forma de referirse al LV (para crear el sistema de ficheros, montarlo, o cualquier uso que le vayamos a dar) será: /dev/NOMBRE_DEL_VG/NOMBRE_DEL_LV. En este ejemplo: /dev/multimedia/musica. En realidad ese nombre es un enlace al dispositivo creado por el subsistema del kernel encargado del LVM, el Device Mapper. El nombre del dispositivo real puede variar y será del tipo /dev/dm-##. Por eso es importante usar /dev/VG/LV, que siempre apuntará al dispositivo real correcto. También podemos encontrarnos referencias en el sistema al LV como /dev/mapper/multimedia-musica, es decir /dev/mapper/VG-LV. Mi recomendación es que uses siempre /dev/VG/LV y así no hay líos 🙂
Al igual que en los pasos anteriores, podemos ver información sobre el LV creado con los comandos «lvs» y «lvdisplay«:
# lvs LV VG Attr LSize Pool Origin Data% Move Log Copy% Convert musica multimedia -wi-a--- 40.00m # lvdisplay -m --- Logical volume --- LV Path /dev/multimedia/musica LV Name musica VG Name multimedia LV UUID KTtf7H-z5kt-68f6-8B8r-cNk0-OUBa-2cRFfe LV Write Access read/write LV Creation host, time curso, 2014-10-30 18:35:31 +0100 LV Status available # open 0 LV Size 40.00 MiB Current LE 10 Segments 1 Allocation inherit Read ahead sectors auto - currently set to 256 Block device 253:0 --- Segments --- Logical extent 0 to 9: Type linear Physical volume /dev/vda3 Physical extents 0 to 9
Podemos ver el tamaño de nuestro LV (en megas o en LEs), el nombre que tiene, el VG al que pertenece, y si en «lvdisplay» añadimos la opción «-m» veremos en donde se encuentra localizado físicamente el LV (que PV(s) a usado el LVM para obtener el espacio del LV, destacado en negrita en el ejemplo anterior).
Ya está listo para usar. Podemos crear un sistema de ficheros en él y montarlo como cualquier otro dispositivo de almacenamiento:
# mkfs.ext4 /dev/multimedia/musica mke2fs 1.42.5 (29-Jul-2012) .... # mount /dev/multimedia/musica /media/ # df /media/ Filesystem 1K-blocks Used Available Use% Mounted on /dev/mapper/multimedia-musica 39663 4587 33028 13% /media
Consideraciones finales
Algo que considero fundamental para poder aprovechar plenamente la flexibilidad del LVM es mantener el máximo de espacio libre en el VG. Es decir, no dar espacio «a lo loco» a los LVs antes de que éstos lo necesiten. Me mata ver como en una intalación nueva todo el espacio del VG es asignado a uno o varios LVs que apenas usan dicho espacio. De nada sirve tener gigas y gigas de espacio libre en un LV. Y un VG sin espacio sin asignar tampoco sirve para mucho (al menos hasta que se aumente con un PV nuevo). Todo espacio libre que pueda estar en el VG nos va a permitir crecer los LVs que lo necesiten o crear LVs nuevos (aunque sólo los necesitemos temporalmente). Si tenemos un VG de 1T y hoy sólo necesitamos un LV que contendrá 100G de información, no le des mucho más (tal vez 150G o 200G), pero deja el resto en el VG para cuando sea necesario. Crecer un LV es sencillo y no causa interrupciones en el servicio, encojerlo es otra historia…
$ exit